
Why System Design Interviews Are Hard
45sReveals a counterintuitive truth: even well-prepared candidates fail because it tests handling ambiguity, not just knowledge.
▶ Play Clip"Title accurately reflects content: a detailed, structured guide to mastering data engineering system design interviews."
This video provides a comprehensive guide to acing data engineering system design interviews. It covers a six-step framework for approaching any design problem, including requirements gathering, pipeline design, data modeling, storage, data quality, and scalability. The video emphasizes that success hinges not just on technical knowledge but on structured thinking and the ability to navigate ambiguity.
System design interviews are open-ended with no single correct answer; candidates must justify trade-offs, unlike DSA problems which have optimal solutions.
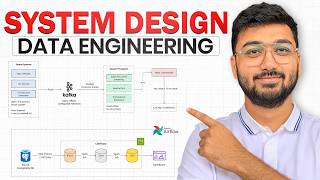
The framework consists of: 1) Requirements gathering, 2) Pipeline design, 3) Data modeling, 4) Storage & file formats, 5) Data quality & observability, 6) Scalability, backfills & data ops.
Spend the first 5 minutes asking clarifying questions about end users, functional needs (who, what, how), and non-functional requirements (latency SLA, volume, availability, data retention).
For an e-commerce platform with 5M daily active users, 30 events/session, 2 sessions/day → 300M events/day (~210 GB/day). This drives decisions: need Spark (not Pandas), partition by date, no streaming needed.
Batch (e.g., daily reports) uses Spark + Airflow; streaming (sub-minute latency) uses Kafka + Spark Structured Streaming/Flink. Lambda architecture combines both; Kappa uses a single streaming pipeline with Kafka as storage.
Covers medallion architecture (bronze=raw, silver=cleaned, gold=aggregated), star schema vs denormalization (OBT), slowly changing dimensions (SCD1/2/3), and partitioning strategies.
Columnar formats (Parquet) are best for read-heavy analytics; row-based (Avro) for write-heavy streaming. Delta Lake/Iceberg add ACID transactions, schema evolution, and compaction.
Key dimensions: completeness, accuracy, consistency, freshness, uniqueness. Data contracts enforce schema at ingestion; observability monitors pipeline health (e.g., Airflow, DataDog).
Idempotency (use MERGE not INSERT), backfills (overwrite partitions), schema evolution (flexible bronze, strict silver/gold).
Design a real-time analytics pipeline for Uber Eats. Two consumers: restaurant partners (sub-2 min latency) and executive team (daily batch). Uses Lambda architecture: Kafka → streaming path (Spark → Redis) and batch path (S3 → Delta Lake → gold tables).
Mastering data engineering system design interviews requires a structured approach: gather requirements, do back-of-the-envelope calculations, design pipelines, model data, ensure quality, and plan for resilience. The key differentiator is making your reasoning visible and justifying trade-offs.
What are the six steps of the data engineering system design framework?
Requirements gathering, pipeline design, data modeling, storage & file formats, data quality & observability, scalability & operations.
03:30
What are the two types of requirements to gather in system design?
Functional requirements (what the system does) and non-functional requirements (how the system behaves, e.g., latency, volume, availability, retention).
05:00
What is the difference between batch and streaming processing?
Batch processes data in large chunks at scheduled intervals (e.g., hourly/daily), suitable when cost matters more than latency. Streaming processes data continuously with low latency (sub-minute), suitable for real-time dashboards and fraud detection.
14:00
What is the Lambda architecture?
Lambda architecture runs two parallel paths: a batch layer for historical data and a speed layer for real-time data, combining results in a serving layer.
16:00
What is the Kappa architecture?
Kappa architecture uses a single streaming pipeline for all data, with Kafka acting as both ingestion and storage. Historical reprocessing is done by replaying events from Kafka.
20:00
What are the three layers of the medallion architecture?
Bronze (raw data as-is), Silver (cleaned and structured data, often with fact/dimension tables), Gold (pre-aggregated data for analytics).
22:00
What is the difference between SCD Type 1 and Type 2?
SCD1 overwrites the old record, losing history. SCD2 keeps both records by adding a valid_from/valid_to timestamp, preserving history.
25:00
Why is Parquet preferred for analytical workloads?
Parquet is columnar, allowing column pruning and file-level statistics, which reduces I/O and speeds up queries that read only a subset of columns.
30:00
What problems does Delta Lake solve over raw Parquet?
Delta Lake provides ACID transactions, schema enforcement, time travel, and compaction (solving the small file problem).
33:00
What are the five data quality dimensions?
Completeness, accuracy, consistency, freshness, uniqueness.
36:00
What is a data contract?
A formal agreement between data producer and consumer defining schema, data types, required fields, and allowed values, enforced at ingestion.
38:00
What is idempotency in data pipelines?
Running a pipeline multiple times with the same input produces the same output (no duplicates, no missing data). Achieved by using MERGE instead of INSERT.
40:00
How should schema evolution be handled in a medallion architecture?
Bronze layer should be flexible (schema-on-read, accept all changes). Silver and gold layers enforce strict schemas with merge schema for new columns.
42:00
The Six-Step Framework
Provides a clear, repeatable mental model that can be applied to any data engineering system design problem.
03:30Back-of-the-Envelope Calculation Example
Demonstrates how simple math drives major design decisions (Spark vs Pandas, partitioning, no streaming) and impresses interviewers.
09:30Real Interview Walkthrough
Applies the entire framework to a realistic question (food delivery pipeline), showing exactly how to structure an answer in 45 minutes.
43:00[00:00] There is a lot of confusion about what exactly to prepare for system design interviews for data engineering. What are the kind of topics? What are the type of questions that are asked? And is it even the same as system design interviews for software engineering? So, to be honest, most candidates study plenty. They read a good amount of books. They've watched enough videos, but the reason why this round is hard isn't completely because of lack of knowledge.
[00:35] But, of course, if you don't have the required bar of knowledge, you will fail by default. What I'm saying is that there are several candidates who still fail this round despite having good amount of knowledge. And it is primarily because it tests how you navigate ambiguity. In DSA, even the hardest problems have a have a solution. They have a destination. They have an answer, right? A two-pointer problem, let's say, has a correct answer. A dynamic programming
[01:09] problem has an optimal substructure. You break it down. You solve the subproblems, and then you arrive at the solution. You arrive at the answer. System design, on the other hand, is open-ended in a way coding questions aren't. And what I mean to say is that there is no correct answer. If you ask 10 different senior senior engineers to design the same ingestion pipeline, you are going to get 10 valid architectures. And each of it will be
[01:44] with different trade-offs. Some on cost, the others on latency, complexity, failure handling, yeah? So, there is no optimal solution per se. You have to justify your choices. And that's why explaining trade-offs becomes very important. The interviewer isn't just checking whether you reached an answer or a solution. They are checking whether your reasoning whether your reasoning holds up when some when they to some of the constraints. And changing some of the constraints can look something like what
[02:19] happens when the volume becomes tonight. What happens when the business who was looking at the dashboard, they are now expecting it in 10 minutes instead of one full day. What happens when a source becomes unreliable? So, this is where your preparation from software engineering system design interview resources and examples like URL shorteners, Twitter feeds, they are not going to work for data engineering system design interviews. The list of topics to cover for system design interviews is
[02:54] large. For example, ingestion patterns, data modeling choices, batch versus streaming trade-off, schema evolution, item potency, backfills, cost and scale, yeah. But the way you approach any of these questions is going to be the same. So, it's really important to note that the way you approach any of these questions is going to remain Every data engineering system design problem, whether it's building a lake house for e-commerce, whether it's building a recommendation pipeline, a fraud detection pipeline, or
[03:28] a customer 360 platform, all of this can be broken down using the same single framework, yeah. And this framework is exactly what we are building today. Hey everyone, I am Afaq Ahmad, solutions architect at Databricks and previously a junior principal data engineer. I work on a day-to-day basis with multiple companies designing and building massive data platforms serving millions of users. And I've also been on the other side of the table having interviewed hundreds of candidates. So,
[04:03] in this video, I am going to give you everything that you need in order to crack data engineering system design interviews. So, for each of the topics, I'm going to tell you not just how to approach that topic, but also how to think like a senior engineer in that room. At the end, I am going to walk you through a real system design interview question that's been asked at companies like Uber and DoorDash step by step
[04:38] exactly how you would answer it in a 45-minute interview. So, if you are preparing for a senior data engineering role at top tech companies, you should not skip any part of this video. So, now let's get started. So, before we dive into the individual topics, I want to give you the map, yeah? So, think of this as your mental framework you are going to carry into every single system design interview, yeah? Regardless of the company, the
[05:13] domain, or the specific question that they're going to throw at you. So, there are six steps, and they work in order. So, one must try to cover as much as possible from these six steps in the system design data engineering interview. So, the first step is requirements gathering, yeah? So, basically, this is understanding the problem even before you draw a single box on the white board, yeah? So, it is understanding more about the system that you've
[05:47] been asked to build. So, you should ask questions around, let's say, who is the user who is going to use my system? What are the functionalities that it is supposed to offer, right? What exactly are the things that it is supposed to do? What are the latency requirements? And what I mean by latency over here is, let's say the end users, the who over here, are a set of people from the marketing team who want to
[06:22] look at a particular number of dashboards, right? Three to five dashboards. So, we need to check with them whether 5 minutes of latency is something that they need, or they are good with one day of latency with the data being refreshed on a day-to-day basis. What is the volume of data that we need to process, right? Is it in megabytes? Is it in gigabytes? Or is it in petabytes? Right? So, knowing all of these facts is
[06:57] drastically going to influence and impact our decisions downstream when we design our pipelines, when we design the overall system. So, that is something that you will see down the line. Number two, the second part that we should cover is pipeline design. So, how does data move from a particular source to a particular destination, right? If you're ingesting data from somewhere, how does it move from that source into our destination, right? What is What is the mode
[07:32] of operation that we're going to choose? Which is either it is going to be batch or is it going to be streaming? What is the architecture that we're going to choose? Is it going to be lambda or is it going to be kappa? Or is it going to be lakehouse? Is it going to be the lakehouse architecture? Which tool are we going to use for orchestration? Yeah, so there are several tools in the market, which is
[08:06] let's say Airflow, Prefect, Dagster, or Mage. And is there a preference towards any of these tools? The third step is data modeling. This is basically deciding how does the shape of our data look like, right? How does the table structure, medallion layer, slowly changing dimension, all of this is going to look like. So, are we going to go ahead with a star or a snowflake schema, right? How are our fact and dimensions How are our fact
[08:41] and dimension going to look like, right? How if you're going with a medallion layer, how are our bronze, silver and gold layer going to look like. Yeah. Where is this fact and dimension going to reside? Is it going to be in the silver layer or in the gold layer? Where exactly it is going to reside? So, in most cases the data model is in the silver layer and then you build aggregated tables, aggregated metrics in the
[09:16] gold layer. And given that we have dimension tables over here, we will also need to think about things like slowly changing dimension. Which one are we going to follow? Is it going to be type one, two, or three? Right? Based on the requirement. Want to take a moment to talk about Educative, who is also sponsoring this video. So, Educative is a fully interactive text-based learning platform, and they've integrated several diagrams and visual explanation, which makes learning
[09:51] a lot easier and interactive. Their legendary Grokking the System Design Interview is one of the most widely used resources by thousands of learners preparing for interviews at Google, Meta, Amazon, and many other big tech companies. So, it really starts with building your foundations with the functional, non-functional requirements, back-of-the-envelope calculations, things like load balancer, databases, caching, right? And it gets your foundation right. Yeah? And then it walks you through more than 13 real system design examples that
[10:25] have appeared in actual interviews. If you want to go deeper, the Advanced System Design Interview Prep Crash Course covers the senior-level harder scenarios, and Grokking the Low-Level Design Interview using object-oriented design principles is actually a fantastic resource for the object-oriented design rounds, where they start with the object-oriented design principles, and then they go deep into design patterns together with solving real-world examples. Like, for example, design a parking lot, design a ride-sharing system, an elevator system, Amazon
[11:00] locker service, and many others. Yeah. So, together, these three pretty much cover every system design interview you are going to run into. Beyond the system design path, Educative now has a full generative AI learning path with courses like mastering the MCP, cursor AI for enterprise. Cursor AI is something most of us use on a daily basis. Agentic system design and cloud code workflows. Yeah. So, exactly the stack you need to stay ahead right now. And finally,
[11:35] if you prefer learning on the go, Educative Go lets you continue lessons, run code, and practice quizzes right from your phone. So, right now, Educative is running a massive 67% discount. So, claim it while it lasts. You will find the link in the description below. And now, let's get back to our topic. Number four is storage and file formats. So, basically, where does your data live, and in which format does it live? Is it in parquet?
[12:10] Is it in Avro? Is it in Delta? Or is it in Iceberg? And what is the storage optimization strategy that we are going to follow? So, there are storage optimization strategies like partitioning, bucketing, and liquid clustering as available on Databricks. So, which of the strategies are we going to follow for optimization, yeah? And this is drastically going to have an impact on cost. Yeah. The next step is basically on data quality and observability. So, how do
[12:44] you know that the outputs that is being produced by our pipeline, they are healthy and they are correct? So, this is basically by setting up certain data quality rules and metrics in place which can help you make the decision. Yeah? And there are other things like testing, monitoring, alerting, SLAs which are going to form the trust which are going to form the trust for our data pipeline and infrastructure that we are going to build, right? So,
[13:19] they are going to build the trust on the design and the pipeline that we are going to build. Yeah? Lastly, we are going to talk about scalability, backfills, and data ops. So, can the system handle 10x the load? So, what happens if something breaks? Are we able to handle failures gracefully? Are you able to reprocess 3 months of of data? Yeah? Is your pipeline item potent? When you run it multiple times, does it behave in a
[13:54] consistent fashion? Yeah? So, these six steps form the core for a data engineering system design interview. Now, here the thing about interviews. Interviewers use a wide and then zoom approach. So, they'll start with a broad question, something like design a data pipeline or design a data pipeline which basically tracks user activity. Yeah? So, it basically tracks user activity for an e-commerce platform. Yeah? It basically tracks user activity for an e-commerce platform and then they're going to
[14:28] drill down into two or three or as many amongst these six topics, these six steps over here. Yeah? So, all right. Let's start with step one, requirement gathering. I would say that most candidates rush through this step. Yeah. They we we basically get overly enthusiastic and we start building boxes on the whiteboard. So, let's take a step back. Always focus on requirement gathering. Try to understand more about the system that you're trying to build because this
[15:03] can seriously cost you the entire interview. So, please pay attention on the first step as we are going to study it. So, here is the scenario. Let's assume that the interviewer tells you design a data pipeline to track user activity on an e-commerce platform. Yeah. And trust me, I've seen this happen. Most of the candidates jump straight to the whiteboard and they would start drawing boxes with Airflow, Kafka, Spark on it, right? Don't do that. Don't
[15:38] start designing a system without fully understanding what it is supposed to do, right? What are you supposed to build? Yeah. Take a step back. Spend the first 5 minutes doing something really very simple. Asking question. So, requirement that gathering is the most underrated step in the entire framework and it is a very simple step that immediately separates strong candidates from the average ones. So, there are two types of requirements that you need to nail down and
[16:13] they are functional and non-functional requirements. Yeah. Functional and non-functional requirements. So, what exactly is functional requirement? Functional requirement means that what does the system need to do. The system that we are building or designing, what does it need to do? And how do you figure this out? How do you answer this question? So, the first thing that you start with is with the end user. You start with the who. Yeah. You start with the end user
[16:47] you start asking questions that who is the end user who is going to use or consume from the system that I'm going to build. So, is it a marketing analyst running SQL? Is it a marketing analyst who is running SQL? Right? Or is it an ML team which is feeding data into a feature store for their recommendation engine? So, is it an ML team? Or is it a product team monitoring real-time product metrics, right? Or is
[17:22] it a product team monitoring product metrics, right? The reason why this question is really important to be asked because this is going to tell you the kind of architecture that you're going to build. Because if we look at these three users, the architecture is going to look completely different. So, marketing analyst for this one, it can simply be a batch architecture, whereas for these two, it has to be a streaming architecture. Right? So, that's why the
[17:57] first question that you need to ask is who, yeah? The second question that you need to ask is what do they actually need, yeah? So, the second question you need to ask is what what do they actually need? Do they need aggregated metrics? Do they need raw level events? Or do they need historical snapshots? Right? Or do they need historical snapshots? Yeah? So, this is the second question you need to ask. And the third question that
[18:32] you need to ask is how are they going to access it, right? The how. How are they going to access it? Is it directly through SQL queries? Is it directly through SQL queries or is it through, let's say, a BI tool like Tableau or Power BI? Yeah, or is it through REST APIs? Yeah. So, let me take a concrete example and tell you how functional requirements are going to look like. So, let's let's take this example
[19:06] for the marketing team. The marketing team basically needs to understand how users move through the purchase funnel. Yeah. So, if you are on on an e-commerce platform, the first thing that you would come would be the home page and then, let's say, you search for a particular product, you view the product, you add the product to cart, and you finally purchase the product, right? So, let me show you how the funnel look like. Uh this one,
[19:41] let's say, is the home page. And then, you search for a product, you view the product, and then if you like the product, you add it to the cart. And then, the product is finally purchased. Yeah. Now, they would want to look at different metrics at each of these stages. And some of these metrics can look like this, right? So, let's say there are 100,000 users, 100,000 users who visited the home page. And then, there were
[20:16] 60K users who finally came to search product page, which means that there is a 40% drop-off. And from here, 30K users came to actually viewing the product, which is a 50% drop-off, higher than what it was earlier. And once a person has viewed a particular product, only 10K users came to the add to cart page, finally added to cart the product that they they viewing, and this is a 67% a much higher drop off. And finally,
[20:51] only 4K users purchased the product, which is 60% drop off, right? So, here it tells us the journey of the user right from starting from the home page starting from the home page to purchasing the product, yeah? And the marketing team would definitely like to slice and dice these numbers by certain dimensions, right? And what can those dimensions or segment look like? So, for example, one of them can be user type. Is it a new user
[21:25] or is it a returning user? Is it a free user or is it a paid user, right? So, they would want to see that what is the purchase rate of new users versus returning users? And is there something that can that they can do about it after reading through the metrics, yeah? The other dimension that they can segment by is device type. Right? So, let's say the conversion rate conversion rate across a desktop is let's say
[22:00] 2% while on mobile it is 6%, yeah? So, this could also signify that the checkout flow across desktop might not be so seamless or it might be broken, yeah? So, this could make them look deeper into the problem statement and then resolve the problem, yeah? So, this basically gives us an idea about the problem that the marketing team would want to solve. So, what is the functional requirement from here? The functional requirement is basically the functional
[22:35] requirement from the marketing team would be that they want to look at funnel metrics. Yeah. Funnel metrics at daily granularity. Segmented by dimensions. And these dimensions can be, for example, user type. This can be device type. And then there could be several other dimensions that could come in, right? And this has to be accessed in Tableau. Right? So, this is something that we need to come up with after talking with the interviewer. Or let's say, when
[23:10] we do problem solving, day-to-day problem solving in your life with business stakeholders, and understand that this is the functional requirement for the system that we have to build. So, the next one now is non-functional requirements. Yeah. Which basically means how should our systems behave? Yeah. So, can it handle 10 TB of data? Can it refresh within an hour? Yeah. So, there are some key areas which we should always dig into whenever we are talking about non-functional
[23:44] requirements. Yeah. So, the first key area is latency SLA. Which simply means that does your data need to be fresh within a minute or is 1 hour acceptable? Yeah. So, if an hour is fine, then you're looking at a batch architecture. So, if an hour is fine, if you're then you're looking at a batch architecture. Yeah. If a minute or less is the requirement, right? Less than 1 minute, then we are looking at streaming. Yeah. Then
[24:19] we are looking at streaming. So, the infrastructure cost, the complexity, operational overhead, all of it is then going to go up. Yeah? So, this one answer alone can change the entire design. So, that's latency SLA. The second one is volume. So, are we ingesting 1 GB of data a day or 10 TB of data a day, right? Are we ingesting GB of data a day, TB of data a day, or PB of data a day? So,
[24:54] this changes every storage and compute decision we make. So, at 1 GB of data a day, you can simply get away with a single node tool like Pandas or Polars. Yeah? But, if you are talking about TB or PB scale, then you need distributed compute like Spark. And not just distributed compute, you also need a serious storage optimization strategy like partitioning, bucketing, or let's say liquid liquid clustering. Yeah? So, that the queries don't end up scanning
[25:29] the entire data set. The third one is availability. Availability simply means how much of tolerance do we have for downtime? Yeah? Can we tolerate 10 minutes of downtime during a production deployment? The last one is data retention, which simply means do we keep everything forever or do we move records to the archive layer after 90 days of usage, right? So, do we keep the records forever or do we move the record to the archive layer to
[26:03] the archive layer after 90 days of usage in order to optimize storage cost? Yeah? So, these are the four areas that you should definitely touch and speak about whenever we are clarifying and trying to freeze our non-functional requirements. Now, let's get back to the original question. Design a pipeline to track user activity on an e-commerce platform. So, here is how the same vague question leads to two completely different answers just based on the requirements alone. Yeah.
[26:38] So, let's take two different scenarios. The first scenario is that of a the consumer is a marketing team. They want daily reports on the user behavior as I mentioned earlier, which pages the people visited, what products were added to the cart, and how the conversion funnel looks like. Yeah. So, they query this in Tableau and they can wait 1 hour for the data to be refreshed. Yeah. So, this is a classic batch pipeline. Yeah. So, this
[27:13] is a classic batch pipeline, your Spark Spark jobs, Airflow orchestration, Delta tables, a data model with facts and dimensions. Now, let's take the other scenario. Scenario number two, where you have where the consumer is an ML team serving real-time product recommendations. Yeah. So, every user action needs to be updated in the model's feature store within seconds. Yeah. So, think of Uber Eats showing you trending restaurants right now, or DoorDash re-ranking the results based on what you
[27:48] browsed just 30 seconds ago. Yeah. So, in these cases, the users' actions need to flow into an online feature store within seconds, and then the model reads those fresh features at inference time. So, this is a streaming architecture. Yeah. Kafka, Flink, or Spark Structured Streaming together with Delta table, feature store, completely different system, right? So, you see the question is the same, but it leads to two different design. Yeah. The requirements are what determine the answer.
[28:22] It's really important to focus on requirements gathering and trying to ask as many meaningful question so that we are able to arrive at the right architecture. Okay, now, here is something I've seen instantly elevates your answer, right? Once you've gathered the requirements, do a quick back-of-the-envelope calculation, right? So, do a quick back-of-the-envelope calculations. Yep. And I'm going to tell you what exactly this means. Yep. So, the reason why I am asking you to do this, and
[28:57] I see most candidates skip this entirely. So, this is basically going to tell the interviewer that you don't just talk theory. You also think in numbers, and those numbers are the ones which is actually going to drive design choices, design decisions, and we'll see how. Yeah. So, let's let's do one together. We will stick with scenario A. We will stick with scenario A, and basically scenario A was the batch pipeline for the marketing team. They want
[29:32] daily reports on user behavior, page views, add-to-cart action, conversion funnel, refreshed every hour, and queried in Tableau. Yeah. So, the first thing that we are going to start with is the users. Right? So, let's say that this e-commerce platform has 5 million daily active users. Yeah? And when you assume these numbers, do it back and forth in discussion with the interviewer. Keep ask ask them whether this number looks reasonable or not. And then based on the
[30:06] discussion, tune these numbers right? So, that it seemed that this is a continuous discussion, right? A design discussion between you and the interviewer. Yeah? So, let's assume that this platform has 5 million daily active users, and each user each user is going to generate 30 events per session. 30 events per session. Yeah? And each of these events, what do these events mean? These events are basically things like page clicks, page views, clicks, searches, add to cart.
[30:41] Yeah? And let's also assume that on on an average on an average, the number of sessions the number of sessions per user equals to Right? So, there are 5 million users. Yeah? Each user does 30 events in a day on an average, and each user has two session. Right? So, let's assume that you log in to amazon.com twice in a day on an average, and you let's say view a particular product, uh see more details about
[31:16] a particular product. If you want to buy it, you add to cart, and then you purchase it, right? So, this is how some of the metrics look like. And again, as I said earlier talk through the inter talk through with the interviewer. Discuss this whether these numbers make sense or not. Yeah? So, in In to calculate the total events per day, now we are going to calculate total events per day, it is simply going to be
[31:51] 5 million users and 5 million users on an average do two sessions in a day and each session is 30 events, right? So, this is going to be 300 million events in one day. Right? So, it is going to be 300 million events in one day. Now, let's try to estimate how much is going to be the size of these 300 million events, right? So, what is what is an event uh going to contain? Right? So,
[32:25] let's assume that one event is going to be one JSON, one JSON, and it is going to contain something like, let's say the user ID, the user ID, session ID, yeah, event type, the timestamp, the page URL, basically things like this, right? So, one event is going to contain all of the detail and let's assume that this event is roughly going to be somewhere between 500 KB, 500 bytes, not kilobytes. 500 bytes to 1 KB. Yeah?
[33:00] So, on an average, let's settle down on a middle number, which is 700 bytes, right? So, the size of one event we are assuming it to be 700 bytes, yeah? So, now if we want to calculate the size of all of the events, the size of 300 million events 300 million events I said the size of 300 million events. It is going to be 300 million into 700 bytes. Yeah. So, this is 210 GB per day.
[33:35] Yeah. And if you're looking at what is the monthly number, just multiply it with 30. 30 It is going to give you 6.3 TB per month. Right? So, this is the volume of data that you're working with. Yeah. And these numbers matter because they directly tell you what you should build and what you shouldn't. Yeah. So, at 210 GB of data per day and 6.3 TB of data per month, we are dealing with distributed processing tools.
[34:10] Yeah. So, we are dealing with distributed processing tools. A single node tool like Pandas or Polars is not going to work. Yeah. So, that is why we have to use something like Spark in order to handle this volume of data efficiently. Right? So, that's the first thing. Based on our calculation, we figured out that we need Spark. We need distributed processing in order to handle this volume of data. And for storage, if let's say you are
[34:44] retaining 12 months of data 12 months of data in your bronze layer, then basically we are talking about, let's say, 6.3 TB per month into 12, which is roughly 75 TB of data in a year. Right? So, we are basically generating 75 terabytes of data in a year, and this is before compression. Before compression, yeah. If we use Parquet, or let's say Delta Parquet, the Delta format, uh then we are talking about roughly 2 to 5x
[35:19] compression. And this is going to be roughly somewhere between 15 to 38 terabytes of data. Right? And this is again very manageable storage on top of S3. Right? This is not a lot. But, you need a serious a very good storage optimization strategy, and the first thing that you can start with is, of course, something very simple like partitioning. So, we have all of the events coming in. You can simply partition by the event date, and
[35:54] then it can be something like YYYYMMDD. Right? So, for per day, you can partition by event date, so that the hourly bad jobs scan only the data that they need instead of the entire data set. Right? So, the marketing team is querying in Tableau with an hourly refresh SLA, and with this, you don't need any streaming infrastructure at all. Right? So, we've seen and understood with this calculation that we don't need any streaming infrastructure because of
[36:29] some of the requirement gathering that we did earlier. Every day of refresh is fine, and therefore, we don't need any Kafka, Flink, or any of that. Right? A scheduled Spark job running through Airflow is good enough. Yeah. So, with this calculation, so, to quickly summarize, with this calculation, let me change the color over here. So, with this calculation, where we calculated what are the number of users on our platform. Right? What do they do on the
[37:03] platform? Like what are the number average number of events that they fire in one session? And we found out that we settled on a number that it is 30 events per session. On an average they do two sessions in a day, and this leads to 300 million events in a day. Then we estimated what is the size of those 3 million events. Yeah? We said that one event is going to be one JSON, which is going
[37:38] to look like this. One JSON is 700 bytes of data, and therefore 300 million events is going to be 210 GB of data in a day, or 6.3 TB of data in a month. So, this tells us that Pandas and Polars is not good enough. We will have to use Spark. Yeah? And coming to the storage decision, if we want to store 12 months of data in the bronze layer, we are talking about roughly 75 TB
[38:13] of data before compression, and 15 to 38 TB of data after compression if we are using storage formats like Delta Delta or simply Parquet. Right? And we also need to partition our data set by event date so that we don't end up scanning the full data sets, right? So, we also settled settled on a storage format, which is Parquet or Delta, right? So, we see we see that with this simple math, we have made four major
[38:48] decisions. Yeah? Number one is the compute engine about Pandas, Polars, and Spark. We are going to choose Spark. About the storage format, which is Parquet or Delta. About the orchestration tool based on the need from the marketing team that they are good with daily refreshes, so we are going ahead with Airflow. And we also ruled out an entire category of streaming infrastructure, right? So, you get a glimpse of how important this back-of-the-envelope calculation is, and it
[39:22] gives you so much of leverage and so much of power during the interview. Step two is pipeline design, and every interviewer is going to ask you some version of this question, right? So, how are you going to move and transform the data from source A to destination B, yeah? And your first job is to figure out are we doing this in batch or are we doing it in streaming, right? So, this is the first thing that
[39:57] you must figure out, yeah? So, let's break down both. Let's first study about batch processing. So, batch is what runs 90% of the pipelines and the workloads almost everywhere, right? So, you you use it when the data doesn't need to be fresh every second. So, if you think of it, it can be hourly reporting, daily analytics, or anything where the cost matters more than latency, right? Where the cost matters more than latency, yeah? So, your standard
[40:32] stack over here is Spark, Apache Spark for the heavy lifting, Airflow, Prefect, or Dagster to be able to orchestrate the whole pipeline, yeah? And the whole pattern looks like you have a source, you have a source, and then you basically extract data from here, yeah? And then you land it into, let's say, an object storage, which is S3 or ADLS. And inside of this, it is going to go through different layers where we call it the
[41:07] bronze, silver, and gold. Right? It goes through all of these different layers, and then this is finally served on to a dashboard. Yeah? So, let's take a concrete example. So, here we have an e-commerce company which needs daily sales report. Yeah? So, there is an Airflow DAG, this Airflow DAG which orchestrates the whole thing over here. It basically runs at 2:00 a.m. at midnight. Yeah? So, the Airflow DAG kicks off at 2:00 a.m., basically pulls up
[41:41] the data from this Postgres database over here. Yeah? And then it basically lands it extracts all of the data and then it lands all of this in the bronze layer. Yeah? So, a Spark job basically takes up all of the data from here, and then it does all kind of cleaning, cleaning transformations and it puts it into the silver layer. Yeah? And then another job basically takes the data in the silver layer and then puts it
[42:16] into the gold layer by aggregating things, right? By aggregating, slicing, and dicing the data by let's say the product, region, and then puts it into the gold layer. Yeah? So, let's say by 6:00 a.m. the data is ready, and then it is connected to the Tableau dashboard which gets refreshed with fresh numbers, right? So, this is batch. It is nothing fancy, but it powers most of the dashboards that you use on a day-to-day basis. Now, what
[42:51] if waiting until 2:00 a.m. is not an option, right? So, we took this example over here where our DAG ran every day at 2:00 a.m. It completed at 6:00 a.m. Right? So, what if waiting until 2:00 a.m. is not an option? So, in that case we use stream processing when we need low latency, right? When we need low latency. So, here I explained earlier that batch becomes very relevant when cost is greater than latency, right? When
[43:25] cost is much much more important than latency, but in streaming latency takes preference, right? And what we desire for is low latency, right? So, we need things like real-time dashboards, fraud detection, event-driven systems, or anything with latency SLA under a minute. Yeah? So, basically your stack over here is Kafka for ingestion, right? Kafka for streaming ingestion and buffering, and then Spark structured streaming or Flink for processing, right? So, Spark structured streaming or Flink for processing, and
[44:00] then this all of this data goes into either Delta Lake for storage, right? Delta Lake for storage, and this is basically for the historical layer. This is basically for the historical analytics layer, and a serving layer like Redis or DynamoDB or Cassandra for low latency real-time needs, right? Something like Redis or DynamoDB. Yeah? Okay, here is how it works. So, your source system, it could be an app, it couldn't be a website, it could be transactional
[44:35] databases, right? So, every click, every transaction, or every status update, those events are going to be pushed into Kafka. Yeah? So, these events are going to be pushed into Kafka. Yeah? So, Kafka is going to act as the buffer over here. And Kafka basically decouples the producers from the consumers. So, events are basically retained in Kafka for a configurable period. It can be days, it can be weeks or months, and then consumers are basically going to
[45:10] read at their own pace using the offsets, right? So, now our stream processor is going to read the data from Kafka in real time, in near real time, right? And this stream processor can be either Spark Structured Streaming, or it can be Flink. Yeah? So, this is basically going to either, let's say, enrich the events the the events which basically came from Kafka. Yeah? With another source, or basically filtering out what's not needed. Yeah? So, the
[45:44] processor does its work, and basically it writes the result to a serving layer like Redis or DynamoDB. That needs to be instantly read by, let's say, an app or a live dashboard. Yeah? So, this is how the flow is going to look like. Now, let's take a concrete example for a ride-hailing company, and we basically say that, let's say, a ride we we take an example of a ride-sharing app, which needs to show drivers in real
[46:19] time their earnings as they complete the rides. Yeah? So, once every ride is completed, the event gets pushed into Kafka. So, once the ride is completed over here, once the ride is completed, the ride completed event generated, and this is basically pushed to Kafka over here. Yeah? Now, that event which gets into Kafka, it basically carries details like, let's say, the fare, the surge, and what is the driver ID and all of that, right? Now, Spark
[46:54] structure streaming is going to read this event. It is going to consume It is going to consume this event, and it is going to enrich it with, let's say, the driver metadata from a lookup table, and it calculates the running total for that driver, right? So, it is going to enrich it with, let's say, driver metadata, and it calculates the running total for that driver ID. Now, once it has done that, it simply writes the result,
[47:29] which is the earnings into the serving layer, which is the Redis in this case, and this is read by the app. Yeah? So, this is how the result gets written into Redis, so that the driver app can pull up their earnings instantly. Now, what if you need both both historical batch data and real-time data in the same system? So, that is where lambda and kappa architecture both come in. Yeah? So, lambda architecture Lambda architecture basically runs
[48:03] two parallel path, right? This is the first one, and this is the second one. So, your data comes in. This is where your data comes in. Yeah? And it splits into two. Basically, the first one is the batch layer that processes the historical data set, right? So, this layer it processes the historical data set. Right? And then the speed layer which handles real-time data as it arrives, right? So, this one basically handles real-time data as it
[48:38] arrives. Yeah? So, both paths they are going to write to a serving layer. Now, the serving layer can either be common or it might not be common, right? And we'll look into a few examples, but overall, this is how a lambda architecture is going to look like. Okay, so let's take an example to understand this. So, think about what a ride-hailing app needs to do simultaneously. When you open the app and when you tap request a
[49:13] ride, your phone, basically the app, sends an event to a streaming service like Kafka, yeah? So, in this case, we've taken the example of managed streaming service for Kafka on AWS, right? So, the moment you open the app, you click on request a ride, this event is pushed to Kafka. This event is basically pushed to Kafka, yeah? So, from here, two independent consumer groups read the same event simultaneously. And those two independent consumers are number one,
[49:48] the streaming group over here. And then you have the batch group over here. Yeah? So, these are the two consumer groups. Now, Flink, which is the first consumer group, it is going to read your request for a ride within milliseconds. Yeah. So, this is basically going to read the ride request within milliseconds. Now, what is also happening in the background is that several drivers, right? Based on their location, they are also sending pings to the managed
[50:22] streaming service, right? So, basically, they are going to send information about the location where they are, right? So, that then only the matching of of me requesting for a ride to different drivers who are nearby can be made, right? So, the driver pings are also coming in over here. And they are also going over here to the first consumer, right? So, then this consumer is going to run an algorithm. It is going to run a simple
[50:57] calculation which calculate the search pricing for my area, and then it is going to write two different results to Elastic Cache. Right? It is going to write two different results to Elastic Cache. The first one is going to be the fare details, and the second one is going to be the driver details. So, this is going to be something like, "Okay, your fare is going to be 330 rupees, and driver X is arriving in, let's say,
[51:32] 4 minutes." Yeah. Now, all of this will happen within a few seconds of you requesting the for request ride on the app, right? So, this is powered by the first layer, which is the streaming service. Now, of course, I'm simplifying the steps. Uh the real steps are going to be more complicated, but this is to give you an inspiration, an idea about how things are going to work like, right? Now, the second consumer is AWS Data
[52:07] Firehose, yeah? And AWS Data Firehose is basically a streaming ingestion and delivery service. So, its job is to read the ride events. Its job is to read the ride events from MSK and flush it to S3, right? So, it is going to flush it to S3. Yeah? So, it doesn't process the data. It simply buffers it along with thousands of other events, and it flushes it to S3. So, your ride request is now permanently stored as
[52:41] it was produced in S3, yeah? Now, another interesting thing to note is that Firehose over here has no idea what the streaming layer is doing, what Flink is doing. So, if Flink goes down for a deployment, Firehose still keeps writing to S3 without interruption. So, we've created two different layers. One is the streaming layer, the other one is the batch layer, and they keep working without interfering or being worried about each other, yeah? So, now once
[53:16] the data has landed in S3, Airflow Airflow is going to trigger nightly jobs. Right? And this is basically to compute metrics that cannot be computed with real-time data. And something that needs historical context, yeah? So, you can envision something like a bronze, silver and silver and gold layers on top of S3. And EMR, which is basically managed Spark in AWS, EMR is basically going to read the the raw the raw data in bronze layer, right? It
[53:51] is going to read the raw data in the bronze layer, and then process it through silver and gold. So, some of the example metrics that it is going to compute, some of the business problems that it can solve are answering questions like which pickup zones have the highest demand on Friday evening between 6:00 to 9:00 p.m., yeah? Which routes have consistently 3x higher cancellation rate? Where drivers should be pre-positioned 2 hours before a cricket match at
[54:26] Wankhede Stadium and yeah. So, these are batch views, heavy in aggregations over historical data, yeah? So, now the serving layer, the serving layer is basically combines the signals from both the batch and the speed layer, right? So, it basically combines the signal from both the batch and the streaming layer. So, this the real-time views, right? The real-time the streaming layer is accurate for what is happening as of this moment, yeah? The the batch layer provides the
[55:00] baseline. It provides the historical context, but neither neither of them is sufficient alone, yeah? The reason for that is real-time data is noisy and it has no historical context. Batch data is accurate, but it is already stale by the time I want to use it, yeah? So, batch data got updated yesterday, but I want to use I want to know the state of something as of now. So, it has already become stale by the time I
[55:35] want to read it, yeah? So, together together they provide the ride-hailing app a very grounded and current view. So, for example, think of something like surge estimate. So, when you open the app tomorrow and request a ride, the app just isn't reading from one place, yeah? So, it is reading from this elastic cache over here. Let me quickly change colors. Uh it is reading from this elastic cache over here, yeah? And then it is also reading
[56:10] from the batch layer over here. Right? It is reading from the batch layer over here. The elastic cache, which is the speed layer, answers for right now. Uh an example could be there are 47 ride requests in Bandra and only 12 available drivers. So, the surge is somewhere around 1.8x, for example, right? And from the batch layer, historically, Friday evenings in Bandra between 7:00 to 9:00 p.m. have an average of 2.1x surge. Yeah? So, based on
[56:45] these two numbers, we can make a more grounded estimate on what the actual surge could be. So, this is a real example where we can use both of the layers in order to estimate a realistic surge. Now, let's talk about Kappa architecture. So, Kappa architecture says, "Why maintain two systems, right? Why maintain the streaming path over here and then the batch path over here? Just use one streaming path for everything. Yeah? So, just use one streaming
[57:19] path for everything. Every event is going to flow through this single pipeline. And if you need to reprocess historical data, you just replay it from Kafka through the same pipeline. So, one code base, one set of logic, and much simpler to operate. Yeah? So, in Kafka in Kappa, uh Kafka becomes your storage. And that is the key difference between Lambda and Kappa architecture. So, Kafka, the key point over here is Kafka is going to become your
[57:54] storage. Yeah? So, Kafka isn't anymore a temporary buffer through which events are going to pass through. You are basically going to configure it to retain data for days, weeks, or even months. So, Kafka become both your ingestion layer and also your historical data store. Historical historical data store. Right? So, here is how it's going to work step-by-step. So, every event is going to flow into Kafka and it is going to stay there. So, every event, this
[58:29] can be an event from an app, from let's say a transactional database CDC change, or from IoT device. It is going to flow into Kafka and it is going to stay there, yeah? So, let's say you set a retention period of 30 days, your stream processor, which is let's say Spark structured streaming, is going to read data from Kafka continuously, process events in real time, and then it is going to write the data into the serving
[59:03] layer, which can either be Redis or DynamoDB, yeah? Or anything else, yeah? So, now let's say your So, so first of all, this is how the basic structure and architecture for Kappa looks like. Now, let's say you want your your business logic changes down the line and you need to reprocess last 2 weeks of data with the new logic. So, in Lambda you would have a separate batch job. It is going to take First of all,
[59:38] it is going to merge the new code and run all of the pipelines for 2 weeks using the new logic, right? In Kafka, you don't have a separate batch system. Instead, what you do is you create a new consumer group in Kafka. So, in Kafka, we are going to create a new consumer group, let's say C2 over here, right? And point it to the offset 2 weeks ago. So, this is going to point to today minus
[1:00:13] two weeks ago. Right? So, that is the offset that it is going to point to. Yeah? And basically, we are going to replay those events through the streaming pipeline. So, Kafka streams those historical events through the processor, and we are going to have a separate processor for replay. It is going to stream all of these events through the processor as if they are happening again, right? So, once the replay catches up to the present, you can
[1:00:48] swap the output and you're done. So, basically once all of the data is ingested, this becomes inactive, this becomes inactive, and this is the one that becomes live. And then, we are done. Yeah? So, the limitation here is if you need to reprocess six months of data, Kafka has to either retain six months of data in storage, which is expensive, or you've already lost that data because, let's say, you've not have had that much uh that
[1:01:22] much amount of a retention period, right? So, replaying millions of events through a stream processor that's designed for continuous small batch processing, it is going to work, but it is going to be much, much slower than a Spark job that can read all of this data parallelly and process it in smaller amount of time, right? It it it it will work, but it is not scalable. So, that is why most companies today don't go for pure
[1:01:57] Kappa. They land the data both in Kafka and in S3 or ADLS for historical processing, which is essentially the lakehouse approach. And I'll leave it for you as homework to read more about the lakehouse architecture. All right, step three is data modeling. Now, most of you feel pretty comfortable drawing out the tables for data modeling, right? It's easy to draw out the fact tables, dimension tables, the medallion architecture, which is simple, bronze, silver, and gold. But,
[1:02:32] in the interview, they don't just ask you to design a data model, right? They are going to push back on it. For example, why not denormalize this? What happens when this dimension changes? How does this perform at scale? Yeah? So, it is not just about drawing tables, facts, and dimensions, figuring out primary keys, foreign keys, and all of that, right? It's much more to that. So, here are four things that you need to understand really well.
[1:03:07] The first one is, of course, the medallion architecture in depth. The second one is star schema versus denormalization. The third one is slowly changing dimensions, mostly SCD one, two, and three. Yeah? And finally, partitioning and other optimization strategies. Yeah? So, first of all, let's start with the medallion architecture. The medallion architecture basically is a layered approach to organizing data in your lakehouse, right? And there are three layers, simply bronze, silver, and gold. Yeah? So, bronze is
[1:03:41] basically raw data. So, let's say this is all your data sets over here. Right? This is your data set residing in this PostgreSQL. All of this data is going to be ingested as is as is in the bronze layer. As is in the bronze layer, right? So, you ingest it exactly how it is coming from the source, your JSON dump or CDC logs. Right? So, your JSON dumps or the CDC logs, they are going to be
[1:04:16] put in the bronze layer as it is, right? And these can be again JSON dumps, CDC logs, raw API responses, you don't transform it. You don't clean it. You store it as is. Now, if something goes wrong downstream, you can always come back and reprocess it in the bronze layer, right? So, that's the philosophy behind bronze layer. Now, silver is cleaned and structured. So, this layer is basically cleaned and structured. Right? So, this is where you
[1:04:51] parse these JSON that has come in and you enforce schemas, you do things like deduplicating records, type casting and all of that, right? So, there are a lot of examples where people build the dimensional data model, your fact and dimension tables live in this silver layer over here, right? So, this is your trusted source of truth for analyst and engineers. Now, finally, gold gold layer is basically they are pre-aggregated, pre-joined data sets that has metrics that
[1:05:26] the analyst can query directly, right? So, let's take a concrete example. Imagine you are building this for Spotify, right? So, the bronze layer is going to contain the song played events. So, this event that you see over here is a song played event JSON. Right? So, this basically every event is going to have, let's say, things like a timestamp, what is the user ID, what is the song ID that was played, for how much duration was
[1:06:00] it played, on which device was it played, what is the app version, right? And similarly, this is another event over here. Yeah? So, this is how uh one of the events from Spotify is going to look like, but we must keep in mind that between different versions of the app. So, we see that this is one version of the app. Between different versions, there might be a schema shift. There might be nulls coming in for certain
[1:06:35] uh fields and columns. There might be duplicates that might come in, right? The second part over here is the silver layer. And in the silver layer, we are going to have our data model. And for this case, we are simply going to have fact streams and dim song. So, fact stream is going to record your user ID, song ID, when was it played, for how much duration was it played, and the device type. So, it's going
[1:07:10] to read this JSON, and then process it, and then put the data in this fact stream table, and the dim songs table. The dim song table is going to contain detail about the songs, which is the song ID, title, artist, genre, release year, and all of that, right? And finally, the gold layer is where your pre-aggregated, pre-joined data sets live. And in this case, this is going to be daily artist streams. So, this is going to
[1:07:45] tell me for a particular artist ID and for a particular date, what were the total streams and what were the unique number of listeners. So, we take all of this, this one, and this one, we join it, aggregate it, and then create this table over here, right? So, this is one table, fast queries, no complex joins required specifically over here because you have already aggregated this over here, and that's the purpose for the gold layer. Now,
[1:08:19] the next topic is star schema versus denormalization, right? So, you'll hear this debate a lot of times. You'll hear this debate a lot of times asking whether we should use star schema or snowflake schema or one big table, right? So, I'm considering star schema at the normalized option and comparing it with the denormalized option, which is one big table, yeah? So, star schema basically means you separate out your facts from your dimensions. So, let's say we
[1:08:54] have orders, we have orders, we have customers, and we have products. So, we separate all of this out into different entities, right? So, orders becomes fact orders. We have a separate table for orders, which is fact orders. Similarly, for customers, we have dim customer. And for products, we have dim product. And BI tools love this approach. They are optimized to work with star schemas. It is normalized, easier to maintain, and the query performance is really strong
[1:09:29] when your joins are indexed very well, yeah? The second one is the denormalized approach. Now, in denormalization, and in this case we are referring to OBT, which is one big table. Yeah, one big table. So, one big table simply means that you pre-join everything into a single wide table. So, basically all of this, right? Orders, orders, customers, and products, we basically join all of this into one single table and that single table is called the OBT
[1:10:04] orders table. So, it contains the order detail, it contains the product details which is category over here, and it contains the customer level details, right? So, this is what a pre-joined pre-joined table [clears throat] means, right? So, we pre-join everything into a single wide table and it removes the joint complexity for downstream user. Yeah, OBT shines really well when you have a specific well-understood query pattern and you want it to be fast as fast as possible.
[1:10:38] So, think of a metrics dashboard where the product teams always query revenue by region and by product category, right? So, they query revenue by the region and by the product category over here. Yeah? Over and let's say they do this over the last 30 days. Over the last 30 days, right? So, the same query every day, 20 different people instead of making 20 all 20 of them hit a five-table join, what we do is we pre-join
[1:11:13] everything once in our pipeline and give them this single flat table, right? So, the scans are fast, there are no shuffles. So, a star schema would mean joining five tables for them every time they're querying. So, this is one of the biggest advantages, but of course there are downsides as well. Say, let's say that the product category the product category that we have over here for a for for a group of products change. So, let's say
[1:11:48] clothes changed to apparel. Right? Now, if you're using the star schema approach, we just need to change this one row over here, right? We just need to change this one row and we are done. But in OBT, the product category is duplicated across several orders. Right? This product category is duplicated across several orders. So, we need to update all of these rows. And there could be in reality, there could be millions of rows that we need
[1:12:22] to update. Now, if you multiply it with every dimension, because there could be several dimensions that we could be using. For example, let's say product name changes, the region changes, right? Your update pipeline becomes a nightmare. So, therefore, in a nutshell, you need to be able to justify choosing one approach over the other by understanding the real-world impact of your modeling choices. The next one is slowly changing dimensions. So, here is the scenario. Let's assume that
[1:12:57] the user upgrades their Spotify subscription from free to premium. So, do you override the old record or do you keep history? Yeah. So, the question is, a user changes from free to premium. Should you override the old record? Do you override or do you keep history? If you override it, that is SCD1. Yeah, so this is override. So, that is SCD1, simple, but you lose history. The reason for that is you can't answer how many users
[1:13:32] were there on the free tier 6 months ago, because you've already overwritten history. Yeah? So, this is what was there in the first case. For this particular user, this person was in the free tier, and then we updated it to the premium tier, and then we've lost history. Yeah? SCD2, on the other hand, what it does is it keeps both the records. Yeah? It keeps both the records. So, the old row gets a valid to So,
[1:14:07] earlier it was this case, which is user 42 was in the free tier. The person started the free tier from 2024, 1st of January 2024. Valid to equals null means that this is the current active tier. But, the moment this person upgraded their tier, what is going to happen is that valid to is going to get updated to the date on which the upgrade happened, right? So, this is going to close the record. Right? It is
[1:14:41] going to close the record saying that the person was on the free tier from this date to this date, and then we are going to insert another row saying that the user is on the premium subscription. The user joined the premium subscription on this date, and valid to is null, meaning that this record is active. The user is currently on the premium subscription. Right? So, now you can very easily query the historical state of any dimension
[1:15:16] at any point in time. And this is really powerful in the sense that it's a standard approach for dimensions where history matters. Right? And some examples could be understanding customer tier over time, the subscription plan, or the user geography over time. The next one is partitioning or optimization strategy. Yeah, broadly optimization strategies. So, the most common and almost always correct default is partitioning by event date. Yeah. So, time series data is almost always filtered by date
[1:15:51] in queries. So, this dramatically reduces the amount of data that is scanned. Yeah. But, also think about high cardinality filter column. If 80% of your queries filter by country or region, add that as a secondary partition key. So, add that as a secondary partition key. The first one can be your event date. And then this one can be your secondary partition key. There are newer optimization techniques like liquid clustering which actually removes the rigidity of fixing
[1:16:26] your partition column up front. So, with this approach of partitioning, you have to fix your partition column up front. If you partition by date, but your query start filtering by region instead, your partitioning strategy goes for a toss, right? It's no more helpful. And changing it means rewriting this whole data set again, right? So, it basically means rewriting this whole data set again. And that's why newer techniques like liquid clustering becomes very handy. It removes the
[1:17:00] rigidity. So, instead of creating fixed physical partitions, it dynamically reorganizes your data based on the columns you want to cluster on. You can cluster on event date and region together. And let's say down the line, if your query pattern changes, you can just update the liquid clustering column. And there is no need of a full rewrite. That's the beauty of it. Topic four is storage and file formats. This topic feels boring, but let me explain you
[1:17:35] with an example why this matters, right? So, let's assume that you have a table with 200 columns, right? So, let's assume that you have a table with 200 columns and a billion rows. Yeah. So, 200 columns and 1 billion rows. Yeah. So, the analyst frequently runs queries that only reads three of those columns. Yeah. So, the analyst frequently runs queries with reads only three of those columns. If your data is stored in a row-based format like
[1:18:10] CSV, the engine reads every single column of every single row because there is no way to be able to skip the data that you don't need. But if we store the same data in a columnar format like Parquet, the engine just reads three of those columns. Yeah. And it simply ignores the other 197 entirely. So, the same data, the same query, just because of the storage format, one scan is the full table, while the other one
[1:18:45] just scans less than 2% of it. So, that is why understanding storage formats is really, really important. So, we are going to talk about three things here. The first one is file format, row-based and column-based. We'll talk about Parquet and Avro. The second one is about Delta Lake and Iceberg and why do they exactly matter? And the third one is about database types, which is the relational and non-relational, and when should you choose either one of
[1:19:19] it? Yeah. So, let's get started with the first one. And you can read about CSV and ORC, which are other formats given that we are covering only parquet and Avro, but they fall into the same bucket which is either row based or column based, yeah? So, to give you a flavor of how row based looks like, let's assume that we have this table, yeah? We have this table over here where we have order ID, name, revenue,
[1:19:54] city and category and this looks just as any other normal relational database table would look like. So, in memory, this whole thing over here is this whole one row is stored as one chunk together, right? And similarly, it will be done for all of the rows, yeah? But if you were to look at how it is stored in a column based format, it is stored differently. So, all the order IDs are stored together, one column. All
[1:20:29] the data for one column is stored together. So, you see all of the orders, they are stored together in memory, yeah? Similarly, for name, revenue, city and category, this is all stored together in memory, yeah? So, first taking the example of column based, which is let's say parquet. Parquet is the default for analytics workload and it is column based, right? So, data is stored in a similar format that we have seen over here, right? Data is
[1:21:04] stored in column by column instead of row by row. So, why does this matter? This matters because let's let's take this query. Select average revenue from sales where city equals Bengaluru, yeah? So, over here it is looking at two columns. The first one is revenue, the second one is Bengaluru, which is the second one is city, which is Bengaluru. Yeah. So, if your table has more than 200 columns, right? It is just going to pick these
[1:21:38] two up, right? So, it is just going to pick up revenue and it is just going to pick up city. These are the only columns that are going to be read. Yeah. So, the other 198 columns are skipped entirely and this is called column pruning. And because the data is stored in a sorted format in parquet files, you have the statistics stored at a file level. Yeah. The engine can skip entire files that don't match your
[1:22:13] filter. So, parquet is why analytical queries are fast and it can be used for anything that is read-heavy and analytical, right? So, I hope you understand why I mentioned read-heavy. Because it's very easy to pick up a column and then read just that chunk of the column over here. Right? If you were doing this on a row-based row-based uh storage format, the same query, what you would have to do in order to compute the revenue, revenue
[1:22:48] is belonging to this row, this row, this row, this row, and this row. You have to end up reading all of the rows, right? And similarly for figuring out which city equal Bengaluru, you have to read this row in order to be able to understand whether city equals Bengaluru or not. Yeah. So, that is why in cases where your operations are read-heavy, column-based format work very well. Their performance is better. Now, let's come to the second
[1:23:23] part which is Avro. We covered parquet. Let's come to Avro and this is row-based. Yeah. This is row-based which makes it faster for write-heavy workloads. So, the previous one was good for read-heavy workloads. This is good for write-heavy workloads. So, think about what's happening when a streaming system is writing data. So, every event, a ride completed, a button clicked, or an order placed, they need to be written as a single complete record one after the other
[1:23:57] as fast as they come in, right? So, a row-based format like Avro is built exactly for this. Yeah. Each event that we see over here, let's say each button click, or let's say each order request, right? Each event is serialized into one complete row. All of the fields are packed together and then written in one shot. There is no overhead of organizing the data by columns. It just comes in, serializes the row, write it, and then
[1:24:32] move on. Yeah. On the other hand, columnar formats like Parquet are just the opposite. So, they need to collect a large batch of rows first and then reorganize the data column by column before being able to write. Now, this reorganization takes time and memory, which is fine for a batch job running every hour or on a day-to-day basis, but this is terrible when you have, let's say, 10,000 events which is coming in, hitting Kafka, and each
[1:25:07] one needs to be written immediately. Yeah. Okay. So, why don't we just dump Parquet files in S3 and call it a day? Yeah. So, a lot of early data data lakes did this exactly. Yeah. So, a lot of early data lakes did this exactly. Now, here's the problem. When you dump raw Parquet files, yeah, when you dump raw Parquet files in S3. Yeah? There is nothing that is managing them, right? They are just files sitting in
[1:25:42] a folder. And what happens when there are two Spark jobs trying to write to the same table at the same time? Yeah? They can overwrite each other's data, your records get corrupted, or go missing, and nobody gets an error. And that is what no ACID guarantee looks like. And that is what no ACID guarantees look like. So, I hope you understand the problem. There is no layer on top of Parquet file that is managing them, and
[1:26:16] you can have multiple jobs which is writing to the file. Both of them can overwrite each other's data, data can get corrupted, data can go missing, and none of us are going to get an error, right? So, it all happened in silence, and this is what no ACID guarantee means. There is also another problem, which is there is no schema enforcement. So, there is no schema enforcement. And what this means is if somebody accidentally writes a
[1:26:51] string into a column that's supposed to be an integer, it simply goes in. So, you won't find out until a pipeline downstream breaks. Yeah? And then, there is this third problem. There is this third problem, which is the small file problem. Yeah? Small file problem. So, when you're reading streaming pipeline when when your streaming pipeline are writing thousands of tiny Parquet files, each one of you KBs, Spark has to open and read every single file. Now,
[1:27:26] this process of opening and closing the file, the IO operation involved has a lot of overhead involved, right? Which makes the queries slower than if you than it would have had to read one big file, right? So, imagine reading one big file and then there are IO operations for opening and closing the file versus doing it on thousands of small files, right? Opening them, closing them, again and again opening them, closing them, and doing it for
[1:28:00] several of such files, right? So, Delta Lake and Iceberg and Hoodie as well solves all of these problems. So, it has many features like asset transactions, multiple writers without data corruption, time travel, query or table as it existed yesterday, last week, last month, schema evolution. So, basically it helps you add a column without breaking your existing pipeline. And then optimize command in Delta which runs compaction. It basically takes all of these small files and optimizes it
[1:28:35] into one a large and more efficient files, right? And that is why these open table formats are really important. So, I've made a detailed video on Delta Lake which is a 5-hour-long deep dive video. If you're interested, do watch that topic. Now, the last thing I want to discuss for storage and formats is basically database types. And this is very popularly asked in system design interviews as in when should you choose a relational over non-relational databases,
[1:29:10] right? So, when you're solving a problem and when you have an opportunity to choose a database, you will have to decide between either of these two, right? Either relational and non-relational and or non-relational, right? So, you choose the relational when your data is structured, when you have clear relationships, when you can think of and evaluate that you have clear relationship between different entities, and you need strong consistency, right? You need acid compliance and you have complex
[1:29:45] queries in place in order to be able to answer your business question. That is when you choose relational databases. Non-relational databases, you choose them when you need flexibility over the structure of data. When you have semi-structured or unstructured data or rapidly evolving data, right? And you can trade strict consistency, right? Strict consistency, something like acid compliance for speed and availability, right? So, something like logs or social media data or IoT data, right? So, that is where
[1:30:19] you would want to choose a non-relational database. Okay, so now everything we've covered so far, pipeline design, data modeling, storage, all of it, yeah? All of it assumes that the data flowing through is correct. But anyone who has worked in production knows that that is a very dangerous assumption, right? So, sources change without any warning, fields go null, row counts drop. And the worst part is unless you have placed thorough data quality checks, the pipeline is
[1:30:54] going to run successfully, write bad data to the tables, stakeholders are going to make incorrect decisions on it before it is even noticed and corrected, yeah? So, this is the problem that we are trying to solve with data quality, and we are going to talk about three topics. The first one is data quality dimension. The second one is data contracts, and the third one is observability. Okay, so when we talk about data quality, we are not
[1:31:29] just saying whether the data is good or bad. There are specific dimension that we need to check for, right? And we are going to talk about data quality dimensions. Right? So, we should divide our checks into each of these dimensions, right? The first one is completeness. Yeah. And by completeness, what I mean is whether all of the data is there or not. So, if your order table usually gets 10 million rows in a day, and today
[1:32:04] it has got 7. 7.5 million orders, something upstream broke, yeah? Or if, let's say, your customer email column is 40% null, that is a completeness problem. The second dimension is accuracy. Yeah. So, accuracy simply means whether your data is correct or not. So, an order amount of negative 500 is incorrect. A delivery time that is before order time is impossible, right? So, these are things that your source system might allow, but your pipeline data quality logic
[1:32:38] should never allow, yeah? The third one is consistency. So, consistency simply means whether the same data agree across different systems, right? If your order table says the total revenue for March is $2 million, yeah? But your payment table says that the total revenue is $1.8 million, something is off. Something is broken, right? So, it simply means whether your data agrees across system, yeah? Point number four, which is the fourth dimension is freshness. Yeah. So, freshness simply
[1:33:13] means whether the data is current enough or not. It is basically says that the SLA the SLA says that the dashboard refreshes every day. Yeah. But, the last update was 3 days ago. So, the SLA says the dashboard refreshes every day, but the last update was 3 days ago. Therefore, we are making decisions on stale data. And the last one is uniqueness. Uniqueness simply means whether there are duplicates or not. Your pipeline retried after a timeout
[1:33:48] and it wrote the same batch twice. Now, every metric is inflated. Yeah. So, these are some of the most important dimension that we should always consider when we are writing our data quality checks. And each of our checks should fall into one of these dimensions, right? So, these dimensions give you a foundation for building your data quality checks. And instead of like vaguely saying that you're going to add some checks, you should exactly say which check
[1:34:23] are you adding and in which dimension it is going to land. Now, all of these checks that you see over here, right? All of these checks that you see over here, these checks catch problems after the data has entered our system. But, what if you could catch structural issues right at the point of ingestion, right? Right at the point of ingestion. And that is exactly what data contracts do. That is exactly what data contracts do. Yeah.
[1:34:57] So, data contract is basically a formal agreement between a data producer and a data consumer. It is going to define what exactly will the producer send, basically the schema, the data types, which fields are required, and what values are allowed, right? So, to keep it simple, you have a data producer, you have a data producer, and let's say this is a microservice. We are consuming data from this microservice, right? And the consumer is basically my pipeline.
[1:35:32] So, there is going to be a contract which is going to define what exactly is going to be accepted from the microservice, right? So, let's let's take an example. Let's Let's say that with a data contract, we are going to agree up front that the payload that this microservice sends, it is going to have order ID as a string, amount as a decimal, timestamp in an ISO format, and the schema won't change without a versioned migration
[1:36:07] and a 2 weeks notice, right? So, if they want to change the schema from V1 to V2, and whatever we agreed, let's say the order ID, right? The amount and the timestamp, and all of those, right? If this is supposed to change from V1 to V2, there has to be a 2 weeks notice so that the migration can take place. Now, if they break the contract, it is flagged even before the data enters your bronze layer,
[1:36:42] right? So, let's assume that this pipeline was putting data in the bronze layer. This is going to fail, and it is going to be flagged even before the data enters the bronze layer. So, in practice, data contracts are enforced through schema registries for streaming data like Avro with a Confluent schema registry, and through schema validation tools like expectations, yeah. So, the key point is data contracts shift quality left, yeah. Instead of catching bad data in your
[1:37:16] pipeline, yeah, instead of catching bad data in your pipeline, you prevent it right at the source. Now, data quality catches problems with the data itself, right? But what about the pipeline that is producing the data, and how do we know that it is healthy? And that is where pipeline level observability comes in, right? So, that is where pipeline level observability comes in, yeah. So, we check if our DAG is running, did it fail, or how long
[1:37:51] did it take? Is it taking 3 hours when it should, let's say, take only 40 minutes, which might mean that either the data volume has spiked or our cluster is under sized. So, all of this can be monitored through an orchestration tool, and let's say you can use Airflow, Prefect, Daxter, and these are easily available through their built-in metrics, yeah, or through other tools like, let's say, DataDog or CloudWatch if you're on AWS. Okay, topic six,
[1:38:26] the final piece, which is pipeline resilient. So, what happens when things break, and they will break, right? How do you rerun your pipelines without duplicating data? How do you backfill years of history if your business logic changes, right? And these things are bound to happen, right? Business logic is bound to change over time. How do we scale and deploy pipelines without bringing production down? Yeah? So, let's start with what I call the golden rule for data
[1:39:01] pipelines, and that is idempotency. Okay? Idempotency. So, here is what it means in simple terms. So, if you run your pipeline twice with the same input, you should get the exact same output, yeah? No duplicates, no missing data. Run it once or run it five times, the result is identical every time, right? And this actually sounds obvious, right? But getting it right in practice takes intentional design, right? You need to intentionally think about it and then
[1:39:35] design your pipelines and code in that way. So, one of the ways you can achieve idempotency is by using a merge instead of insert for incremental loads, yeah? So, you can use a merge statement instead of insert for incremental loads, right? So, a merge is going to update a record if it exists or insert if it doesn't exist. Whereas an insert is just going to add rows. So, if you run an insert twice, you will have
[1:40:10] duplicate, but if you run a merge twice, you will end up with the same number of records. Next one is backfills. Yeah? Backfills. And what exactly is a backfill? So, to simply put it, it is when you need to rerun your pipeline over historical data that has already been processed. And this actually happens quite often. Yeah, it happens quite often with data engineering team. So, let me give you two real scenarios. Scenario one is let's say
[1:40:45] where you find a bug, your pipeline has been calculating delivery duration as delivered at minus created at. Yeah, now instead of calculating delivered at minus dispatched at. So, it has been wrong for let say 3 months. Every report, dashboard, and metrics based on the delivery time is incorrect. So, you fix the code, but now after fixing the code, you need to rerun your pipeline, and you need to reprocess 3 months of data with the correct logic.
[1:41:19] So, that's one scenario. The second scenario could be your company has always counted total orders as every order placed. But now the business team decides that cancelled orders within 24 hours, they shouldn't be counted. And they want the total orders to mean that orders that were only fulfilled. Yeah. So, going forward, your pipeline applies the new filter, but the old reports are overstating orders. Yeah. So, we simply need to reprocess the old data. First of all,
[1:41:54] fix the code, make changes to the code, and then we need to reprocess the old data with the updated definition. Yeah. So, if your pipeline is idempotent and if you're using Delta Lake or Iceberg, you can directly overwrite the affected partitions. Yeah. So, let's say if from day X to day Y right, you have partition which is 20260101 until 2026 0401, you want to override all of these partitions, you can directly override all of the affected
[1:42:29] partitions, right? Because these table formats support acid transactions, the right is atomic. And by atomic, what we mean is that either the right completely happens or if it fails in the middle, nothing happens, right? Everything is rolled back. So, either the entire partition gets replaced or nothing changes. If the job fails halfway, the old data is still intact. And your downstream consumers never see partial data. So, you just rerun the pipeline for those affected dates, and
[1:43:04] it simply overrides the partitions cleanly. Now, let's talk about schema evolution, yeah? Let's talk about schema evolution. So, at some point, your upstream sources are going to change the schema, yeah? It is not going to happen every day, but at some point in time, it will happen. And if you are not prepared for it, it will break your pipelines downstream. So, here's what it looks like in practice. So, let's say the payment teams adds a new
[1:43:38] column, which is a discount code to their order event. Or let's say the mobile team renames user location to device location. Or an API you are ingesting from silently changes a field from an integer to a string, right? Now, none of these are very big changes, right? None of these are dramatic changes, but any one of them can cause your Spark jobs to fail and your tables to write garbage or your dashboards to show incorrect data,
[1:44:13] yeah? So, the question is, how do you design your pipeline so that it is able to handle the changes gracefully. And the approach is to be flexible at the bronze layer, but be strict at the silver and gold layer. So, be flexible at bronze and strict at silver and gold. Yeah. So, at bronze you simply accept everything as is. Whatever your source code sends, you land it. You don't validate it. You don't enforce or you don't
[1:44:48] reject anything, right? If a new column shows up, it simply gets added, and Delta Lake supports this option with the merge schema option. Right? With the merge schema. Delta Lake supports this using the merge schema option. So, it automatically accommodates new fields without failing the pipeline. And again, this is intentional. Your bronze layer is your safety net, yeah? So, you want every piece of information to land over there, your raw data to be captured, even if
[1:45:23] the shape or form changes, yeah? But, by the time your data move from bronze to silver and from silver to gold, you enforce a strict schema. Right? You enforce a strict schema. And why do we do so? We do so because the analyst, our dashboard, our ML pipeline, they all depend on it. They expect, let's say, the order amount to always be decimal. They expect the user ID to always exist. So, if a new column appears
[1:45:57] upstream, it lands in bronze automatically, but it doesn't reach silver until the pipeline code explicitly maps it, right? Maps it, validates it, and decides where it belongs. The schema evolution absorbs changes at the bottom and then enforces consistency at the top. So now we've covered all of the principles and concepts, right? So let's take all of them and let's put everything that we've learned so far, that we've covered into action. So I'm going to walk you
[1:46:32] through a complete system design interview question right from the start to the end, yeah? So we're going to cover all of the topics that we have learned so far. However, please keep in mind that the interviewer might take a wide and then a zoom approach. So they might go deep into some topics that might be of more interest to her. So for example, let's say pipeline design or data quality or data modeling, right? Based on their
[1:47:07] interest, they might want to deep dive into some of the topics more than the other. So here's the question. Design a real-time analytics pipeline for a food delivery platform like Uber, Uber Eats, Zomato and Swiggy, right? So we have to design a real-time analytics pipeline for a food delivery platform like Uber Eats, Swiggy, Zomato. Yeah. So the platform needs to track different things like order events, delivery metrics, and provide both real-time operational dashboards for restaurant partners
[1:47:42] and daily aggregated business reports for the executive team, yeah? So basically, this pipeline has two kind of consumers. The first one is basically those restaurant partners who want to see metrics like what are what is my total earnings as is of today? What are the total number of orders that we have delivered so far? What is the pending orders, right? So, there is an operational dashboard. Yeah, there is an operational dashboard requirement and then there is
[1:48:16] a daily business report requirement. Daily business report requirement. So, this is the first one and this is the second one, yeah? So, the second one is basically for the more for the executive team, the finance team, so that they're able to look at metrics on a day-to-day basis. So, I hope the question is clear. All right, so you've heard the question and I want you to resist the urge to start solving it immediately, yeah? I know
[1:48:51] it's tempting, but the best thing you can do in the first 5 minutes is not to design anything, yeah? So, just say, "I'd like to ask a few clarifying questions before I start." Um and and trust me, honestly, the interviewer is expecting this, yeah? In fact, they're waiting for it. So, if you skip it and jump straight to the tools, they will let you do so. They won't stop you. But, they're already noting that you didn't
[1:49:26] think about the problem first, right? So, here are the first few questions that I will ask, yeah? So, the first question is who are the end users? Who are the end users, right? And this is basically some part of it is answered in the question itself, right? What we've understood is there are two groups. The first one is those restaurant partners who need to see their live orders and an executive team who needs business report. So,
[1:50:01] we understand that there are two audience over here and they have completely different SLA needs, yeah? So, the first one is restaurant partners and this one is the executive team. Yeah? The second question that we should ask is what exactly are those latency SLAs, right? So, what exactly are those latency SLAs? Yeah? So, for the restaurant dashboard, it could be under 2 minutes end to end, yeah? And for the executive dashboard, the daily batch delivery is
[1:50:35] totally fine, yeah? So, we can simply say that for this one less than equal to 2 minutes is fine and this one one day is completely fine, yeah? So, that would be the second question that we would ask. The third one is what is the approximate data volume? What is the data volume, right? And let's say the answer is we have 5 million orders in a day, yeah? We have 5 million orders in a day. And
[1:51:10] during peak load dinner rush between 7:00 to 9:00 p.m., it is around 500K orders per hour. During peak load, it is 500K orders per hour, right? And that is an interesting metric. The other question that we can ask is what are the events that we are tracking, right? So, what are the events? What are the events that we are tracking? And this could be, let's say, six event types. The order placed, and then after the order
[1:51:45] was placed, the restaurant confirmed the order. So, first one is order placed, restaurant confirmed, driver assigned, driver picked up, driver delivered, and then if the order was canceled, order canceled event, right? So, six events, they would happen chronologically, which is order placed, restaurant confirmed, driver assigned, driver picked up, driver delivered, or order canceled, yeah? And then finally, what I would also like to ask is what is the data retention? So, let me write six over here
[1:52:20] first, yeah? And for data retention, let's say we have 2 years for analytics and 90 days for real-time service. So, we have 2 years for analytics and 90 days for real-time service. Yeah? Now, remember what we covered earlier, back of the envelope calculation, and this is where to apply it, right? So, we've got our requirements, we've got our volume estimates. Let's quickly run the math so that we start designing, and our choices are backed by actual
[1:52:54] numbers yeah? So, what have we said earlier? We said that there are 5 million events 5 million events per day, right? We said that there are 5 million events per day and there are six event types. Right? So, there are six event types. Correct? And those six events, just to reiterate, they're basically order cancelled, restaurant confirmed, driver assigned, driver picked up, driver delivered, or order cancelled. Yeah? So, this basically gives us 5 million events into six
[1:53:29] events. This is basically 30 million events in a day. Right? So, this is 30 million events per day. Now, let's get the per second rate. So, 30 million events, which is this number over here. And per day is basically 24 into 60 into 60. Yeah? So, if you do the calculation, roughly this is going to give you this number, 350. Yeah? So, this means that we are getting 350 event 350 events per second. Yeah? So, we
[1:54:04] are getting 350 events per second. But, remember we also said during the peak hour, there are 500K orders. Yeah? During dinner rush. So, we should also take that into consideration. So, 500K 500K per hour. And therefore, this is also going to have six events. This means that 500 thousand into six events, which is 3 million. And this is basically per hour, right? So, if we take 1 hour, which is 60 into 60 seconds over here, This
[1:54:39] is roughly going to give me 833 events. Yeah. So, this makes something very clear. The range the range of events could vary could vary somewhere between 350 to 833. Right? Roughly on an average, the number of events per second could be somewhere between 350 to 833. Yeah? And this is something that is very manageable for Kafka. So, this is something that is very manageable. Very manageable for Kafka. Even a modest three-broker cluster can handle this easily.
[1:55:13] We don't need an aggressive partitioning strategy over here. Something like six to 12 partitions gives us a good parallelism for our Spark structured streaming consumers. Yeah. Now, let's think about uh storage. So, now let's think about storage. So, each order event, let's say, is a JSON. So, each order event is a JSON. And this basically contains attributes like order ID, event type, timestamp, restaurant ID, driver ID, customer ID, coordinates, and all of that, right? So, again,
[1:55:48] let me just note it down quickly. Order ID, the event type, timestamp, event type, and all of those, right? And let's say that this is 1 KB. Let's say that this is 1 KB in size per event, right? This is again an assumption, and this is something that we need to confirm in communication back and forth with the interviewer, right? So, based on what the interviewer says, tune this number. Yeah? So, there are 30 million events
[1:56:23] in a day, yeah? And 1 KB of data per event, this basically gives me 30 GB of data per day. Right? So, this gives me 30 GB of data per day. And if you remember, when we talked about retention, the interviewer said that it should be 2 years of retention. So, this should turn to be something like 30 GB per day into 365 into two. And this leaves me with somewhere around 21,900. Roughly, this is 22
[1:56:57] TB. Right? So, this is roughly 22 TB of data in the bronze layer before compression. If you add parquet compression on top of it, which should roughly give you two to five x of compression, yeah? So, it is somewhere going to be between four to 11 TB. Right? This number is going to go down two to five x. And it is going to be four to 11 TB. And we are looking at four to 11 TB
[1:57:32] on disk. And this is something really, really manageable for S3 or ADLS. Right? And for the Now, let's come let's come to the real-time serving layer. So, for the real-time serving layer, which is, let's say, Redis in our case, let's think about what data actually sits in Redis. So, the restaurant dashboard doesn't need every row event, yeah? It doesn't need every row event. It needs a small set of precomputed metrics per restaurant. So, things like, um,
[1:58:07] current active orders, average delivery time in the last hour, orders completed so far. Yeah. So, let's say that is roughly 10 to 15 field. Right? So, let's say that it is 10 to 15 fields per restaurant. Correct? If we have 50,000 active restaurants, and again, confirm this with the interviewer. Let's say we have 50K active restaurants. We have 50K active restaurants. And each of each each restaurant dashboard recorded 1 KB of data. Yeah. Each restaurant's dashboard
[1:58:42] recorded 1 KB of data. That means we have 50K into 1 KB, which is just 50 megabytes of data. Right? At any given time. For single Redis instance can hold this in memory very easily. So, this is exactly why we do back-of-the-envelope calculations, right? So, now we understand that our Kafka setup, based on the calculations that we have done over here, based on the calculation that we have done over here, the Kafka setup is very manageable.
[1:59:16] That is number one. We have also understood that our storage cost, right? And our storage volume is also something very predictable and manageable. And lastly, for the serving layer, for the serving layer, Redis handles the serving layer comfortably, right? And most importantly, we now know the scale of this problem. And it's moderate. It's not massive. So, now let's move on to the next part, which is pipeline design. Okay, before we step into pipeline design, I want
[1:59:51] you to internalize this, right? So, we are not building two different systems. We are building one data platform with two consumption patterns, right? So, we are building one data platform with two different consumption patterns. The first one is for those restaurant partners and the second one is for the executive team. Yeah. So, the source of truth is one, basically our event stream. Everything else Everything else is a shaped view of that stream, right? Optimized for a
[2:00:26] specific consumer's latency and query pattern. So, basically what I want to say is we have one event stream, which is Kafka. And here is where our events are flowing into. And there are two consumers. The first one is the streaming path, right? And the second one is the batch path. Correct? So, this one is for the restaurant partner dashboard. Right? And this one is for the executive reports. Yeah. So, the restaurant dashboard needs data within minutes.
[2:01:01] The executive reports needed by next morning. So, we are designing [snorts] a lambda style architecture with two parallel paths. Yeah. So, the keyword is lambda style architecture. Right? We are designing a lambda style architecture with two parallel paths. The first one is going to be streaming path for real-time operations, and the second one is the batch path for historical analysis. And this is how it is going to look like. Yeah. So, path A is going to
[2:01:35] be the streaming path. Yeah. Path A is going to be the streaming path. Order events are going to come in. They are going to hit Kafka. And this is going to be partitioned by restaurant ID so that events for a given restaurant, say ordered, Spark streaming is then going to pick all of this up. It is going to calculate the running metrics, and then it is going to write the result to a NoSQL database. And this
[2:02:10] is connected to a live restaurant dashboard that the restaurant partners can see. Now, during the interview, you can possibly face some questions, and it is worth digging deep into this, right? So, how are the metrics going to be calculated? Yeah. And what exactly are those metrics? Now, path B is the batch path. Yeah. So, batch path is It is getting the same events from Kafka, which is getting synced to S3 or ADLS as a raw parquet.
[2:02:45] Yeah. So, if we were using AWS, this is going to be MSK, which is managed streaming for Kafka, and then you would need Firehose in between, which can read the events from here, and then dump it over here, right? And then once the data lands in S3, you can have a whole data pipeline over here, which basically takes the data from bronze, cleans it, puts it in silver, and then creates aggregated records in gold, which can
[2:03:20] then be picked up by the executive team, and then be shown on the daily dashboards, right? So, now we have designed a robust pipeline. Yeah? So, an interesting thing to note is, after you've designed uh this architecture, right? The interviewer might want to dig deeper into some of the topics, right? So, for example, they might want to dig deep into Kafka over here, right? There can be some questions around, let's say, exactly once versus at least
[2:03:54] once semantics. So, those can be one one type of question. The second one could be, how do you handle, let's say, the partitioning strategy, retention, log compaction, things like watermarking, what how do you deal with late arriving data, and all of that, right? So, all of that can come over here if the interviewer wants to dive deep into Kafka, right? Some other interviewers might want to dive deep into, let's say, Spark, yeah? So, in Spark, they
[2:04:29] can ask you questions like uh Spark internals, things like AQE, uh things about, let's say, the query plan at a high level, right? Uh what does shuffling mean, what are the different kind of join strategies, and how do they differ, how would you want to store your data in this uh in all of these layers, right? What kind of uh data optimization and storage strategies will you apply? Will you apply things like partitioning, bucketing, reordering, liquid
[2:05:04] clustering, and all of that, right? So, there can be a very deep discussion based on the areas that the interviewer is interested in once you come up with this architecture, yeah? So, I would suggest you to brush up uh your knowledge about say things that you have worked on the past. If you worked with Kafka, brush up your knowledge, right? Uh strengthen your basics about Kafka, strengthen your basics about uh Spark. Let's say if you've used
[2:05:39] Delta or Databricks, um try to understand it in more detail so that you're able to answer questions and you're able to explain what you've already done, right? You're able to reason and back your answers with logical explanations. Next we are going to use a medallion architecture with three tiers. Let me quickly erase this out. Right? So, these three tiers are basically going to be the bronze, silver, and the gold tier, right? So, bronze as we know
[2:06:13] is going to be the raw ingestion layer. Order events are going to land at JSON from Kafka. And one order event could be something like this, right? So, it will contain things like the order ID, what is the event type, and the event type is order placed. When was the event uh when did the event happen? Uh which restaurant to which was the order placed? Which customer placed the order? And things like this, right? So, this
[2:06:48] is basically going to land in the bronze layer, right? We don't clean anything here. This is your immutable source of truth. Yeah. Now, next up in the silver layer, this is where we are going to build our data model. Right? Which is basically our facts and our dimensions. Yeah. Basically, our facts and dimensions. The most important ones are fact orders, dim restaurants, where all of the restaurant details are going to be stored, right? And then dim
[2:07:23] drivers. Dim drivers. Yeah. So, these three are going to be the most important tables. For fact orders is basically going to contain details like your order ID, restaurant ID from where did the restaurant the order come in, right? Uh the driver ID, the person who is going to deliver the the order. Yeah. Cust- order placed at, delivered at, canceled at, total amount, delivery duration, right? Things like that. So, this table can either be partitioned or liquid
[2:07:58] clustered by the orders date. Yeah. Similarly for restaurant it's going to have the restaurant ID, the name, city, and let's see another column such as active since. And the driver the driver table can have the driver ID, the name, city, rating, and the vehicle type. Yeah. So, there can be other tables as well over here in the data model. For example, let's say fact payments, fact subscriptions, dim food items, and all of that. But, let's keep
[2:08:32] it simple to basically serve as an inspiration to build the final one, right? And finally in the gold layer, we are going to have two tables, right? Aggregated tables, which is basically the daily restaurant metrics. Right? Daily restaurant metrics, which is over here. Yeah. And for the restaurant dashboard, actually we'll only have just one table, right? The live one is going to be served from here. And the daily one is going to be built in the
[2:09:07] gold layer, which is going to be served over here. Yeah. On the storage, we are going to use Parquet over here. And then all of the rest from here to here, it is going to be the Delta format. Yeah. Okay, so the next thing that we should think about is data quality checks. Yeah. Let me quickly erase all of this over here. So the first thing as we studied earlier is we should apply data contracts at
[2:09:42] the schema registry so that we are able to find out malformed or incorrect records which are not correct in the structure right at this point. Yeah. So that's the first thing that we should do. The second thing is applying data quality checks at the bronze layer. Yeah. So what you can do is basically we can check things like let's say event type. So this event type is always going to be limited uh by certain types of
[2:10:16] valid values, right? So this can be any of order placed, driver assigned, order picked up, order delivered, or order canceled, right? So we can check for this, right? That's one of the checks. We can also check whether this combination of order ID plus event type is not duplicated, right? So if it happens, we just log, we don't drop. Yeah. So this is a weird case that I'm talking about, right? Ideally it shouldn't happen, right? But of
[2:10:51] course these are what data quality rules are meant to detect. And then there can be other checks as well that we can place over here. For example, uh checks on customer ID, they should not be null and all of that, right? By the way, a very important point to note is that all of these checks are going to fall in those dimensions that we discussed. So similarly you can apply checks on the silver layer. Some examples
[2:11:26] are going to be the most simplest example is the null check on different kind of attributes. The other one is referential integrity checks, right? Referential integrity checks. What this simply means is that every restaurant ID in let's say the fact order table. So, we created a fact order table over here. Every restaurant ID in the fact orders table, they must exist in the dim restaurants table, right? So, orphaned orders mean that a restaurant was never on-boarded.
[2:12:01] Yeah. The other one that you can also apply is based on certain kind of business rule, and several such business rules might exist, right? So, let's say the delivery duration in minutes. The delivery duration in minute should be between 1 and 180. Right? A more than 3-hour delivery duration is, let's say, a data error. Yeah. Some other checks that you can apply is time-based consistency logic. So, for example, picked up at must be after order placed
[2:12:35] at, right? And delivered at must be after picked up at. So, these are also some kind of sense checks, right? So, pick up can be only after the order has been placed, and delivered can only be after the order has been picked up. And a few other ones that you can also apply is some kind of volume based checks, right? So, what we basically do is we compare the current day's number of rows with, let's say,
[2:13:10] the last 7-day rolling average, right? And we see whether it is going out of proportion or under proportion, right? And then we flag based on the results, yeah. So, all of these checks again are going to go in those dimensions that we discussed, and I leave it to you as homework. So, that is how we can create data quality checks for the silver near now. I'm taking some examples of the gold layer. In the gold layer,
[2:13:45] we are going to aggregate all of our data and we can apply some kind of aggregation and checks. For example, let's say the cancellation rate percentage must be between 0 and 100. Yeah. Average delivery minutes must be positive and it should be a logical value. It shouldn't be like in 4 hours 5 hours. That number has to be decided by the business. Yeah. So, again, this is how you can place meaningful data quality checks at the
[2:14:20] bronze, silver, and the gold layers. Now, the last part is about scalability and operations and I will leave you with four things that can be discussed with the interviewer in this section. And something we've already discussed in detail before. Number one is going to be your backfill strategy right? It's going to be your backfill strategy. So, what if the aggregated table that you have created over here, some logic changes and you need to refresh the values
[2:14:54] over here. So, how are you going to make sure that you can seamlessly rerun the pipelines with the updated logic for a given start and end date. Yeah. Number two is going to be item potency. Yeah. So, how are you going to make sure that your pipelines can run n times with the same inputs and it will produce the same output. And this is a non-negotiable requirement. And the last one is schema evolution. So, basically, bronze
[2:15:29] should use schema on read schema on read. Yeah. And then silver should enforce a strict schema, right? Silver and gold should enforce a strict schema. Right? With but with merge schema enabled for any new addition, yeah? And that's it, yeah? That's it. So, we've designed a complete system starting from the requirements, data model, pipeline, storage, data quality, operational readiness, scalability, and operations, right? So, we've discussed all of this, and that is exactly the flow you should
[2:16:04] try to follow as much as possible in an interview, right? And it's completely okay if you're not able to cover every topic that we've discussed over here in details. That is completely fine, but if you're able to show the structure, it tells that it tells the interviewer that you are very well rounded in your thinking, yeah? Okay, so, let me leave you with this. The candidates who fail system design interviews aren't the ones because they don't
[2:16:39] have knowledge about Kafka or Spark Structured Streaming or let's say Delta tables, right? Of course, if you don't have knowledge, you will fail the interviews. What I mean to say is that people who have complete knowledge about these tools are still failing interviews, right? And they fail because most of them most of them lack a structure. They jump straight to the tools without understanding the problem in detail, without spending a lot of time on requirement gathering,
[2:17:13] right? They design for the happy path without thinking too much about the failures, the problems that could come up in the design yeah? And the candidates who pass, they basically slow down. They spend a lot of time with the interviewer asking questions, drilling down on requirement gathering, right? They ask questions and make their reasoning visible. What I mean by making the reasoning visible is that they're very vocal, and they shout out when they they to choose
[2:17:48] one technology over the other, right? When they have to choose one path over the other yeah? Uh they highlight about the pros and cons of one over the other. And this is very important. It's very important to be able to reason your choices, to be explain your thinking about choosing one approach over the other, right? So, that is what I mean by making your reasoning visible in front of the interviewer. And that is the real difference.
[2:18:23] If this was useful, please don't forget to like, share, and subscribe to my channel. I put out deep dive data engineering content, the kind of stuff that actually moves the needle in your career. I hope this was interesting to you, and I will see you in the next video.
⚡ Saved you 2h 18m reading this? Transcribe any YouTube video for free — no signup needed.