What is Caching?
45sExplains a core concept in a simple, relatable way, making it highly educational for beginners.
▶ Play ClipCaching in REST APIs improves performance and scalability by reducing database load. This guide covers in-memory caching, request-level caching, conditional caching, cache invalidation strategies, and multi-layer caching.
Caching stores frequently accessed data to save time and resources, improving API performance and scalability.
Redis and Memcached store data in memory for fast retrieval. Example: caching user profiles with a TTL of 300 seconds.
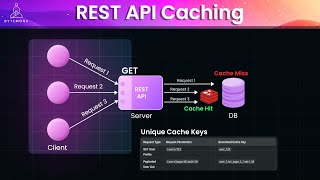
Caches entire API responses based on unique request parameters (e.g., user ID, pagination params). Uses cache keys like 'user_123' or 'user_list_page_2_limit_10'.
Uses ETag and Last-Modified headers. Client sends If-None-Match; server returns 304 Not Modified if unchanged, saving bandwidth.
Write-through (sync update), write-behind (async update), and TTL-based eviction (auto-expire). Each balances performance and consistency.
Browser cache, CDN, application cache (Redis), and database. Example: e-commerce product image request traverses layers for optimal speed.
Implementing caching across multiple layers—browser, CDN, application—with proper invalidation strategies ensures fast, scalable, and production-ready REST APIs.
"Title accurately reflects content; video delivers a comprehensive caching tutorial for REST APIs."
What is the purpose of caching in REST APIs?
To improve performance and scalability by reducing load on databases and servers.
Name two popular in-memory caching tools.
Redis and Memcached.
00:33
What does TTL stand for and what is its purpose in caching?
Time To Live; it automatically expires cache data after a set time to prevent stale data.
01:27
How does request-level caching generate unique cache keys?
By combining request parameters such as user ID or pagination parameters (e.g., 'user_123' or 'user_list_page_2_limit_10').
03:11
What HTTP headers are used in conditional caching?
ETag and Last-Modified.
04:56
What status code does the server return when the ETag matches in conditional caching?
304 Not Modified.
05:36
Describe the write-through cache invalidation strategy.
The cache is updated synchronously whenever the database is updated, ensuring the cache always holds the latest data.
07:08
What is a disadvantage of the write-behind strategy?
Cache might temporarily hold stale data until the asynchronous update completes.
08:03
List the four layers of caching mentioned for an e-commerce product image request.
Browser cache, CDN, application cache (Redis), and database.
09:59
Redis Cache Hit Example
Shows the instant retrieval of cached data, demonstrating the core benefit of caching.
01:00304 Not Modified Explanation
Clear explanation of how conditional caching saves bandwidth by returning a status code without body.
05:36Multi-Layer Caching Journey
Illustrates the complete path of a request through browser, CDN, application, and database caches.
09:46[00:00] Caching is like keeping a shortcut to frequently travel paths. It saves time and resources. In the world of APIs, caching can dramatically improve performance and scalability by reducing the load on databases and servers.
[00:16] But how do we implement caching effectively in REST APIs? Let's go step by step, starting with the basics. The application layer is where most caching happens in best APIs.
[00:33] By caching frequently accessed data, we can cut down on redundant database queries and computations making our API much faster. In-memory caching is a great first step. Tools like Weddys and Memcached are popular choices.
[00:47] They store data in memory making retrieval almost instantaneous. And here is a simple Java example where we are using Redis, an in-memory data source, to cache user profiles and minimize database hits.
[01:00] Here the RedisClient.GetUserId retrieves the profile from Redis using the user id as the key. If the data exists, it's a cache hit and the profile is returned instantly. No need to query the database.
[01:14] If the data isn't found in Redis, it's a cache miss. In this case, the application fetches the profile from the database. This is the fallback mechanism. The database query ensures that the user still gets the correct data even when the cache is empty.
[01:27] Once the data is retrieved from the database, we cache it in VEDIS for future requests. Here the StetX method stores the profile in VEDIS with a time to live or TTL of 300 seconds
[01:39] or 5 minutes. This means the data will automatically expire after 5 minutes, ensuring the cache doesn't hold outdated information. Now think about the next request for the same user profile.
[01:52] Instead of hitting the database again, the application fetches it directly from Redis in milliseconds. This reduces latency, minimizes load on your database and improves the overall user experience.
[02:04] By using Redis as a caching gear in your REST API, you can handle higher traffic, reduce response times and lower the load on your database. It's a simple yet powerful technique to make your application scalable and efficient.
[02:17] layer caching happens deeper within the application logic, often focusing on specific data or computation results rather than entire responses. Request level caching is all about caching entire API responses for specific requests.
[02:31] It's tied to individual API calls and is typically implemented based on unique request parameters for example query strings or request headers. This approach is specially useful for read heavy operations like get request where the
[02:44] data doesn't change frequently. Here is the basic workflow. When a client makes a GET request, the server first checks if a cache response exists. If it does then it a cache hit The server immediately returns the cache data If it doesn it a cache miss The server processes the request generates the response and caches it for creative use Request caching relies on generating unique cache keys for each combination of request parameters
[03:11] A cache key is a unique identifier used to store and retrieve cache data. It returns a specific request for data set and ensures that cache responses are correctly associated with a corresponding request.
[03:24] This ensures that responses for different queries don't overwrite each other. For example, consider an API that fetch a paginated user list. So let's say you have an API to fetch user details. Here you can use the user ID as a key.
[03:37] This ensures that the cache response is typed specifically to user 123. A request for user 456 would use a different key say user underscore 456. Or you can consider an API that returns a paginated list of users.
[03:52] Here use a combination of the query parameters to create the key. For example, consider an API method that fetches paginated user list. Here we first generate a unique key user list underscore page underscore two underscore
[04:05] limit underscore ten. It ensures that the response for each request variation is stored separately. Redis client dot get cache key checks if the response is already cached. If it's a cache shift, the response is returned immediately.
[04:18] And if it's a cache miss, meaning if the data isn't found in Redis, the database is queried using fetch users from database page comma limit and once the data is retrieved it is stored in bed with a TTL of 600 seconds or 10 minutes.
[04:32] This ensures the state data is automatically removed. Request level caching is ideal for read heavy APIs. These are the APIs with frequent gut success and relatively static data and endpoints that
[04:44] involve relatively complex computations for large database queries. For example responses with parameters like page or limit. Now what if the client only needs data that has seen since their last request?
[04:56] Conditional caching is a technique that ensures clients receive updated data only when necessary, minimizing random data transfers. It's an efficient way to reduce bandwidth usage and improve API responsiveness by leveraging
[05:08] HTTP headers like ETag and Last Modified. ETag is its unique identifier for resource version and Last Modified is the timestamp of the last update to a resource.
[05:20] Let's see how this works. the server first calculates an ETag for the resource using the hash of its data. The current ETag acts as a unique identifier for the specific version of the user data. On subsequent requests, the client sends the ETag in the if-none match header.
[05:36] The server compares the client if-none match value with the current ETag and if they match, it means the data hasn't changed. The server responds with a 304 not modified status and and no response body saving bandwidth.
[05:50] If the ETag doesn't match or isn't provided, the server returns the full resource and the new ETag. The client then stores the new ETag for future requests. And here is a sample client interaction In the first request there is no ETag sent by the client and the server responds with a 200 OK and a response body In the subsequent request client sends an ETag and the server checks for the ETag
[06:16] If unchanged, it sends the response as 304 not modified and if it is changed, it sends the response with 200 OK and headers with new ETag and updated data in the body.
[06:28] This showcases how ETag-based conditional caching minimizes unnecessary data transfer and ensures clients always get the latest data when needed. By leveraging ETag and last modified headers, it ensures faster responses, lower bandwidth
[06:41] usage and an overall better user experience in REST APIs. Now as we have learned, caching is powerful, but stable or outdated data can lead to inconsistencies.
[06:53] So to ensure users get accurate data, we need strategies for cache invalidation. That is the methods to update or remove cache data when the underlying sources changes. Let's explore three common approaches with detailed examples including the use of Redis.
[07:08] In the write-through strategy, the cache is updated synchronously whenever the database is updated. This ensures that the cache always holds the latest data. So here the application writes the data to both the database and the cache at the same
[07:22] time. The cache stays in sync with the database. So reads can be served directly from the cache. The main benefit of this approach is that it ensures the cache is always up to date. It's simple to implement for read heavy systems.
[07:35] But it's slightly slow to write due to synchronous nature of cache updates. And so every database triggers a cache update. In the write-behind strategy, the cache is updated asynchronously after the database
[07:48] is updated. The database remains the source of truth and the cache update happens in the background. As you can see in the code, here the application writes through the database first and then a background process, for example a queue or thread, updates the cache after the write
[08:03] is complete. And so, it has faster write since cache updates are default and suitable for high write throughput systems. But again cache might temporarily hold still data until the update is complete.
[08:15] And it is also more complex implement due to the asynchronous handling. And finally we have TTL based eviction. In this approach, cache data is automatically expired after a set time to live or TTL.
[08:29] Once expires, the cache either fetches fresh data from the database or deletes the entry. So here data is returned to the cache with the TTL value and when the TTL expires, the cache entry is removed or refreshed. For example, here is how TTL based
[08:43] addition works in Venice. Here the data expires in five minutes ensuring it doesn't linger longer than it should. Now the choice of invalidation strategy depends on your system requirements. A write-through strategy is best for read
[08:57] heavy workloads where cache accuracy is critical but it has slow writes. A write behind is for write heavy workloads where cache freshness can tolerate But again there is a temporal clash staleness And TGL is data with predictable or time expiration for example product prices or
[09:16] session tokens. But it still has potential for stale data within the TTR. Cache invalidation ensures that your cache data stays fresh and accurate, avoiding stale responses that can frustrate your users. By carefully choosing the right strategy, right through, right behind
[09:32] or teacher-based addiction, you can balance performance and consistency to meet the needs of your application. Caching becomes truly powerful when implemented across multiple layers of the system, each designed to handle specific types of data closer to the user.
[09:46] This approach optimizes performance, minimizes server load, and delivers faster responses. Let's break this down step by step with an example. So imagine a user is requesting a product image on an e-commerce website.
[09:59] The journey of this request involves multiple layers of caching. When the user's browser first loads the image, it stores it in the cache. If the user revisits the page or navigates back, the browser retrieves the image locally
[10:11] without even contacting the user. This is the fastest layer of caching and ensures instant access for repeated requests. If the browser cache doesn't have the image, the request is forwarded to a CDN or Content
[10:24] Delivery Network. A Fugian is a network of servers distributed globally, designed to cache and serve content like images, videos and static files. For example, if the user is in London, the image might be served from a Fugian server
[10:37] in the UK rather than the origin server, reducing latency and server load. And if neither the browser nor the Fugian has the image, the request reaches to your application's API server. Here an application layer cache like Redis or Namcache stores the metadata or frequently
[10:54] access data about the image. For instance, the API server could cache metadata like image URL, resolution or compression format. This reduces the need of repetitive database queries ensuring
[11:06] the backend remains efficient. And finally, if the cache misses at all layers, the server fetches the image metadata from the database. This is the last resort and typically the slow step. Once the data is retrieved, it spars through the layers updating the caches for future requests.
[11:22] Guys, I have also explored CGMs and application layer caching in detail in my previous videos. These topics are part of comprehensive playlist which you can find in the playlist linked in my description. So, bringing it all together, with the techniques we have explored so far, you use in-levery
[11:40] caching for frequently accessed data, you implement request level caching for predictable GET responses, you can leverage conditional caching for up-to-date bandwidth efficient interactions, ensure consistency with robust cache invalidation strategies, and combine
[11:55] all layers such as browser, CDN, and application for the ultimate performance. With this blueprint, you can design best APIs that are not only fast but also scalable and production ready.
⚡ Saved you 0h 12m reading this? Transcribe any YouTube video for free — no signup needed.